


ماشین لرنینگ یک شاخه از هوش مصنوعی است که با استفاده از الگوریتم ها و مدل های ریاضی، به کامپیوتر اجازه می دهد که از داده های جمع آوری شده یاد گرفته و پیش بینی هایی انجام دهد. در واقع، با این تکنولوژی، کامپیوتر می تواند به صورت خودکار به دنبال الگوها و روندهایی در داده ها بگردد و برای پیش بینی های آینده از آنها استفاده کند. ماشین لرنینگ در حوزه های مختلفی مانند تشخیص چهره، ترجمه ماشینی، تشخیص الگو، پردازش زبان طبیعی و ... به کار می رود.
الگوریتم های یادگیری ماشین
الگوریتمهای یادگیری ماشین یا Machine Learning Algorithms در واقع مجموعهای از قوانین و الگوریتمهایی هستند که توسط کامپیوتر به صورت خودکار و برای یادگیری از دادهها استفاده میشوند.(به بیان دیگر ماشین لرینگ شاخه ای از هوش مصنوعی است که به ماشین ها امکان میدهند بدون برنامه نویسی صریح از داده های ورودی یاد بگیرند). این الگوریتمها از چندین نوع الگوریتم مختلف تشکیل شدهاند که هر کدام مزایا و معایب خود را دارند و بسته به نوع دادهها و مسئلهای که قرار است با استفاده از آنها حل شود، انتخاب میشوند.
به عبارت دیگر، الگوریتم های یادگیری ماشینی شامل مجموعه ای از قواعد و روش های آماری هستند که با استفاده از داده های ورودی، مدل هایی را ایجاد می کنند که قادر به پیش بینی و تفسیر داده های جدید هستند.برخی از معروفترین الگوریتمهای یادگیری ماشین شامل رگرسیون خطی، شبکههای عصبی، درخت تصمیم، ماشین بُردار پشتیبان (support vector machine)، دسته بندی نزدیکترین همسایه، دسته بندی ناپارامتریک و الگوریتمهای خوشهبندی و... هستند. هر کدام از این الگوریتمها دارای قابلیتها و کاربردهای مختلفی بوده و برای مسائل متفاوتی از آنها استفاده میشود.دستهبندی یا Classifier یک الگوریتم یادگیری ماشین است که میتواند ورودی را به یکی از چند دستهی از پیش تعریف شده تقسیم کند.
الگوریتمهای یادگیری ماشین در داده کاوی، یکی از کاربردهای جذاب این تکنولوژی است. در داده کاوی، الگوریتمهای یادگیری ماشین میتوانند به عنوان ابزارهایی برای بررسی دادهها و شناخت الگوهای موجود در آنها، استفاده شوند.از طرفی، داده کاوی به مجموعه ای از فرآیندها و الگوریتم های مرتبط با محاسبات آماری و یادگیری ماشینی اطلاق می شود که برای شناسایی الگوها، تحلیل داده ها و استخراج اطلاعات مفید از داده های بزرگ و پیچیده مورد استفاده قرار می گیرند.برخی از مهمترین الگوریتمهای یادگیری ماشین در داده کاوی عبارتند از: درخت تصمیم، کلاسبندیهای بیزی (Bayes)، ماشین بردار پشتیبانی، شبکههای عصبی و کاهش ابعاد. این الگوریتمها قادر به پردازش حجم بالایی از دادهها بوده و میتوانند به راحتی برای پیشبینی، دستهبندی و خوشهبندی دادهها مورد استفاده قرار گیرند.
در ادامه سعی خواهیم کرد تا هر کدام از این الگوریتم های مهم را به صورت جداگانه بررسی کنیم:
-
درخت تصمیم
در ماشین لرنینگ، درخت تصمیم نوعی روش یادگیری است که به وسیله آن دادهها به دستهبندیهای مختلفی تقسیم میشوند. در این مدل، یک سری سوالات پرسیده شده و با توجه به پاسخ هایی که از دادهها دریافت می شود، درخت تصمیم هر داده را در دستهای قرار می دهد.هر شاخه درخت، از دادهها یک سوال میپرسد و برای هر پاسخ، زیر مجموعه های مختلفی به آن شاخه اضافه میشود، تا در نهایت به برچسب نهایی برای هر داده دست یابد.
-
دسته بندی بیز
کلاسیفایر بیز (bayes classifier) به مدل پیش بینی احتمالی یا تصادفی برای دستهبندی دادهها مشهور است. این الگوریتم مبتنی بر قاعده بیز بوده و احتمال هر دسته را محاسبه و با استفاده از این احتمالات، بهترین دسته را برای نمونه ورودی تعیین میکند.برای یادگیری این الگوریتم، ابتدا باید احتمالات هر دسته از دادهها محاسبه شوند. سپس با استفاده از این احتمالات و ویژگیهای مختلف هر داده، احتمال تعلق به یک دسته مشخص برای دادههای جدید تخمین زده میشود.
-
ماشین بُردار پشتیبان (support vector machine)
SVM یا ماشین بردار پشتیبانی یک الگوریتم یادگیری ماشینی است که برای مسائل مربوط به دسته بندی و رگرسیون استفاده می شود. در این الگوریتم، داده ها در فضای چند بعدی از هم تفکیک شده و به دو دسته اصلی تقسیم می شوند.سپس یک سطح تصمیم گیری به نام ماشین بُردار ساخته می شود که برای جداسازی داده ها به شکلی بهینه مورد استفاده قرار می گیرد. SVM با استفاده از تابع های هسته (kernel) مانند تابع خطی، چندجمله ای، گوسی و ... می تواند به راحتی با داده های پیچیده و غیر خطی کار کرده و دقت بالایی در پیش بینی و دسته بندی داده ها داشته باشد.
-
شبکه های عصبی
شبکههای عصبی بر پایه ساختار سلولهای عصبی مغز بشر و حیوانات طراحی شدهاند. در این الگوریتم، شبکهای از سلولهای عصبی مصنوعی به صورت خودکار، از الگوها، یادگیری خود را فرا خواهد گرفت. این الگوریتم کاربردهای مختلفی دارد، نظیر تشخیص تصویر، ترجمه زبان، تشخیص صدا و غیره.این شبکهها از بردارهای اطلاعاتی تحت عنوان ورودی (input) به عنوان سیگنال ورودی استفاده و بعد از گذر این سیگنال از چندین لایه از نورونها، خروجی (output) را تولید میکنند.هدف استفاده از شبکههای عصبی، آموزش آنها برای تشخیص الگوها و روابط پنهان در دادهها و ارائه پاسخ مناسب به سوالات پیچیده است.شبکههای عصبی به دلیل قابلیت تشخیص الگوهای پیچیده و توانایی کار با دادههای ناهمگن، در حوزههای مختلفی از جمله پردازش تصویر، تشخیص گفتار، ترجمه ماشینی و پیشبینی دادهها مورد استفاده قرار میگیرند.
-
رگرسیون خطی
در رگرسیون خطی تلاش میشود تا با توجه به ویژگی دادهها، برای یک مجموعه دادهای، خطی به عنوان بهترین حالت یافته شود. این خط با یادگیری بیشتر به مرور زمان، بهصورتی بهینه می شود که فاصله بین دادهها و خط را کمینه کند.این الگوریتم در زمینههای مختلفی همچون پیشبینی قیمت خودرو، پیشبینی فروش و ... استفاده میشود. در رگرسیون خطی، متغیرهای وابسته و متغیر مستقل تعریف شده و با توجه به آنها، مدلی برای پیشبینی مقدار متغیر وابسته ارائه میشود.
-
دسته بندی نزدیک ترین همسایه
در الگوریتمهای ماشین لرنینگ، نزدیک ترین همسایه به معنای یافتن دادههای شبیه به داده مورد نظر است که نزدیکترین فاصلهی اقلیدسی به آنها را دارند. به این صورت که با مقایسه ویژگیهای دادهها و محاسبهی فاصله اقلیدسی بین آنها، نزدیک ترین داده به دادهی مورد نظر پیدا میشود.
برای دو نقطه در فضای چند بعدی، فاصله اقلیدسی برابر با جمع مجذور فاصله بین هر بُعد از دو نقطه محاسبه میشود.این الگوریتم برای دستهبندی دادههای دقیق عمل میکند و محاسبات آن ساده است. اما برای دادههای پِرت و سرشار از نویز، عملکرد مناسبی ندارد. همچنین در بعضی موارد ممکن است با مشکل بزرگی در ارائه دادهها روبرو شود.
-
دسته بندی ناپارامتریک
دستهبندی غیرپارامتریک به دستهای از الگوریتمهای یادگیری ماشین اطلاق میشود که پارامتر قبلی مشخصی ندارند. این الگوریتمها برای دستهبندی و پیشبینی دادههای جدید استفاده میشوند. الگوریتمهای غیرپارامتریک شامل روشهایی مانند نزدیکترین همسایه، درخت تصمیم، شبکههای عصبی، ماشین بردار پشتیبان و مدلهای گرافیکی بیزین می شوند.این الگوریتمها با استفاده از دادهها، یاد میگیرند که چگونه برای هر نمونهی جدید، باید آن را دستهبندی کنند. در الگوریتمهای غیرپارامتریک، تعداد پارامترهای مدل برای یادگیری از دادهها اهمیتی ندارد و همچنین برای ساخت مدل، نیازی به کشف توزیع خاصی برای دادهها نیست.
-
الگوریتمهای خوشهبندی (Cluster algorithms)
این الگوریتمها به دنبال گروهبندی دادهها به شکلی هستند که اعضای هر گروه شباهت بیشتری با یکدیگر داشته باشند و از اعضای گروههای دیگر متمایز باشند.از مزایای استفاده از الگوریتمهای خوشهبندی میتوان به موارد زیر اشاره کرد:
- برای دادههای بزرگ و پیچیده بسیار کاربردی است.
- درک بهتر از ویژگیهای دادهها و روابط بین آنها.
- قابلیت کاهش ابعاد دادهها.
از جمله الگوریتمهای خوشهبندی میتوان به K-Means، DBSCAN و Hierarchical Clustering اشاره کرد.در ماشین لرنینگ، اندازه دادهها به تعداد و حجم دادههایی که برای آموزش و یا پردازش الگوریتمهای ماشین لرنینگ استفاده میشود، گفته میشود. این میزان میتواند در مصرف حافظه و زمان محاسبات الگوریتم تعیین کننده باشد. در اَبَر داده (Big Data)، اندازه دادهها معمولا بسیار بزرگ است و نیاز به مدیریت خاصی دارد.
در اینجا "ابعاد داده" یا ابعاد ورودی در ماشین لرنینگ به تعداد ویژگیهای موجود در هر نمونه از داده ها گفته می شود. به عنوان مثال، اگر در یک مجموعه داده برای هر نمونه، ۳ ویژگی وجود داشته باشد، آنگاه تعداد ابعاد داده برابر با ۳ خواهد بود. در ماشین لرنینگ، افزایش تعداد ابعاد داده می تواند منجر به پیچیدگی بیشتر در مدل و کاهش دقت پیش بینی ها شود.
ماشین لرنینگ با پایتون
پایتون یکی از زبانهای برنامهنویسی است که لایبراری و ابزارهای مورد نیاز زیادی را برای انجام ماشین لرنینگ در اختیار برنامهنویسان قرار داده است. به عنوان مثال، کتابخانه Scikit-learn یکی از پراستفادهترین کتابخانههای ماشین لرنینگ در پایتون است که به صورت رایگان در دسترس قرار گرفته و قابلیت اجرای الگوریتمهای یادگیری ماشینی مختلف را داراست.برای پیادهسازی الگوریتمهای یادگیری ماشین در پایتون، میتوان از کتابخانههایی مانند Scikit-learn، TensorFlow و Keras استفاده کرد. این کتابخانهها قابلیت پیادهسازی انواع الگوریتمهای یادگیری ماشین را دارا بوده و با استفاده از آنها میتوان به راحتی برنامههایی را در پایتون نوشت که از یادگیری ماشین استفاده میکنند.برای مثال، کتابخانه Scikit-learn شامل الگوریتم های مختلفی مانند رگرسیون، دسته بندی، خوشه بندی، تحلیل عاملی، تحلیل افتتاحیه، رده بندی، بازیابی اطلاعات و... است. همچنین، این کتابخانه ابزارهایی را نیز فراهم می کند که برای پیاده سازی یک روند یادگیری ماشین لازم است، از جمله ابزارهای پیش پردازش داده ها و تحلیل اجزای اصلی (PCA) و ارزیابی مدل ها.با استفاده از این کتابخانه، توسعه دهندگان می توانند به سرعت الگوریتم های یادگیری ماشینی خود را پیاده سازی کرده و به سادگی داده ها را پیش پردازش کنند.
مثالی از ماشین لرنینگ با پایتون
یکی از مثالهای استفاده از scikit-learn برای یادگیری، یک "مدل ساده برای تشخیص اعداد دستنویس" است. به عنوان مثال، میتوانیم از مجموعه داده MNIST استفاده کنیم که شامل تصاویر اعداد دستنویس با ابعاد 28x28 پیکسل است.در این مثال، میخواهیم یک مدل ساده را با استفاده از روش k-NN آموزش دهیم تا بتواند عددی را که در تصویر ورودی نشان داده شده است را تشخیص دهد.در اینجا چند خط کد برای انجام این کار لازم است:
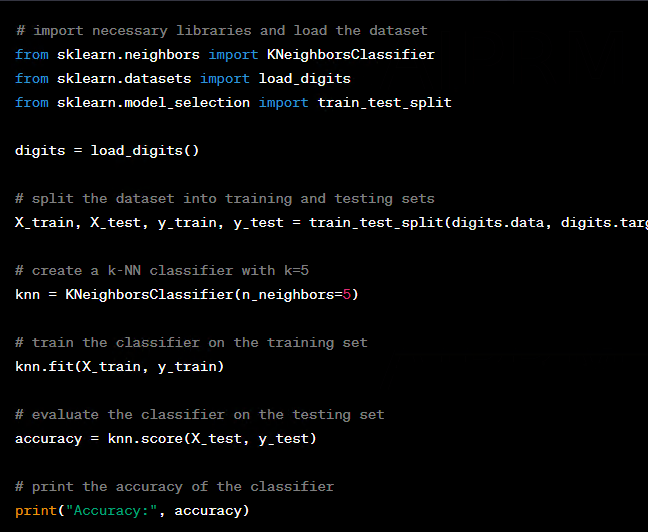
در این کد، ابتدا کتابخانههای مورد نیاز و مجموعه داده MNIST با استفاده از تابع load_digits لود شده است. سپس با استفاده از تابع train_test_split، مجموعه داده به دو بخش آموزش و آزمایش تقسیم شده است.در ادامه، یک مدل k-NN با k=5 ایجاد شده و با استفاده از تابع fit بر روی بخش train، آموزش داده شده است. سپس با استفاده از تابع score، دقت مدل روی بخش آزمایش (Test) محاسبه شده و در نهایت با استفاده از تابع print، دقت مدل (accuracy) چاپ شده است.
جمع بندی
در کل، یادگیری ماشین یک روش هوش مصنوعی است که برای بهینهسازی یا پیشبینی خروجی یک سیستم یا فرایند به کار میرود. الگوریتمهای یادگیری ماشین، به دلیل قابلیت استفاده در مسائل مختلف و افزایش اطلاعات موجود در جامعه، در حال حاضر بسیار مورد توجه و استفاده قرار میگیرند. Python به عنوان یک زبان برنامهنویسی قوی و ابزارهای آن مانند Scikit-learn، یکی از برترین گزینه ها برای پیادهسازی الگوریتمهای یادگیری ماشین محسوب می شود که در این مطلب به آن اشاره شد.








.jpg)


ارائه دهنده خدمات زیرساخت یکپارچه ابری